Decision Tree Classification
- 정의
- Python Example
from sklearn.datasets import load_iris
import io
import pydot
from IPython.core.display import Image
from sklearn.tree import export_graphviz
import matplotlib as mpl
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
iris = load_iris()
X = iris.data[:, [2, 3]]
y = iris.target
from sklearn.tree import DecisionTreeClassifier
tree1 = DecisionTreeClassifier(criterion='entropy', max_depth=1, random_state=0).fit(X, y)
pd.DataFrame(iris.data, columns=iris.feature_names).head()
def draw_decision_tree(model):
dot_buf = io.StringIO()
export_graphviz(model, out_file=dot_buf,
feature_names=iris.feature_names[2:])
graph = pydot.graph_from_dot_data(dot_buf.getvalue())[0]
image = graph.create_png()
return Image(image)
def plot_decision_regions(X, y, model, title):
resolution = 0.01
markers = ('s', '^', 'o')
colors = ('red', 'blue', 'lightgreen')
cmap = mpl.colors.ListedColormap(colors)
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = model.predict(
np.array([xx1.ravel(), xx2.ravel()]).T).reshape(xx1.shape)
plt.contour(xx1, xx2, Z, cmap=mpl.colors.ListedColormap(['k']))
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1], alpha=0.8,
c=[cmap(idx)], marker=markers[idx], s=80, label=cl)
plt.xlabel(iris.feature_names[2])
plt.ylabel(iris.feature_names[3])
plt.legend(loc='upper left')
plt.title(title)
return Z
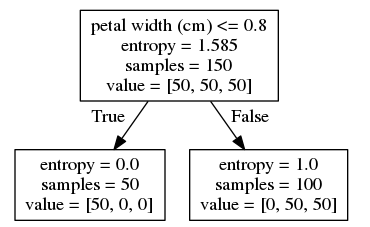
draw_decision_tree(tree1)
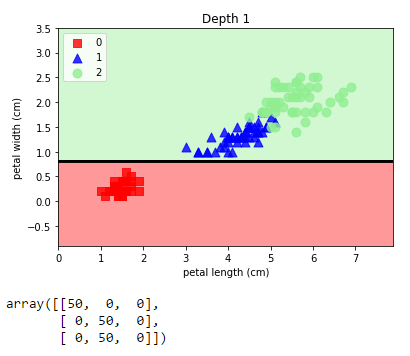
plot_decision_regions(X, y, tree1, "Depth 1")
plt.show()
confusion_matrix(y, tree1.predict(X))
tree5 = DecisionTreeClassifier(
criterion='entropy', max_depth=5, random_state=0).fit(X, y)
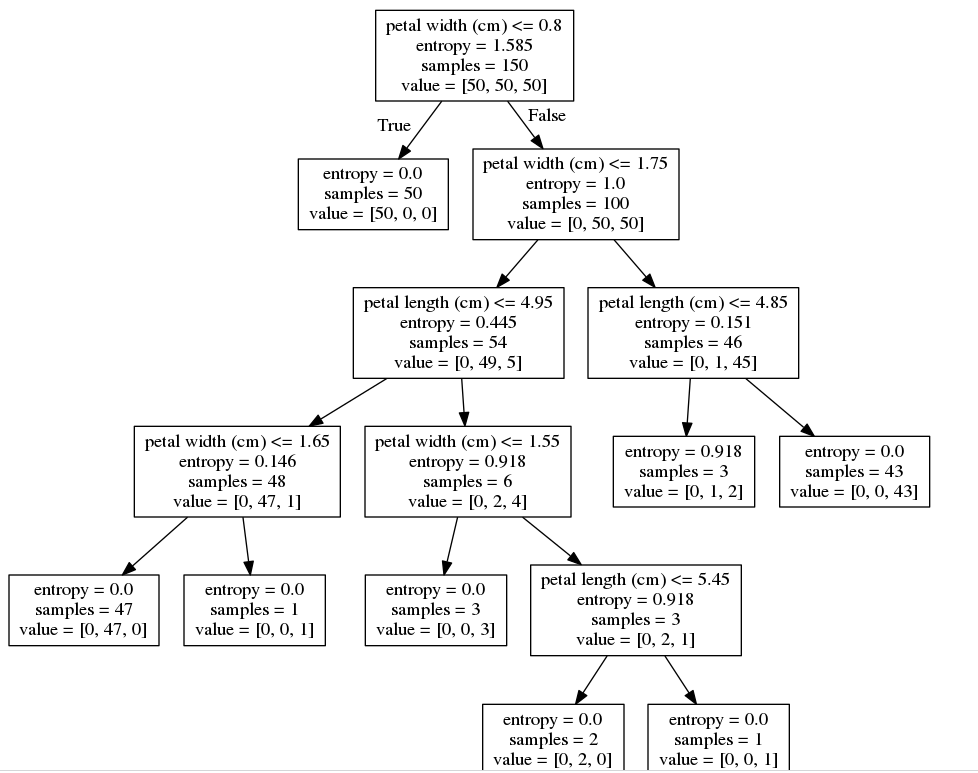
draw_decision_tree(tree5)
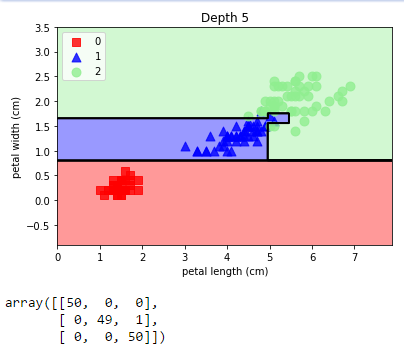
plot_decision_regions(X, y, tree5, "Depth 5")
plt.show()
confusion_matrix(y, tree5.predict(X))
# Titinic Survived Predict
import seaborn as sns
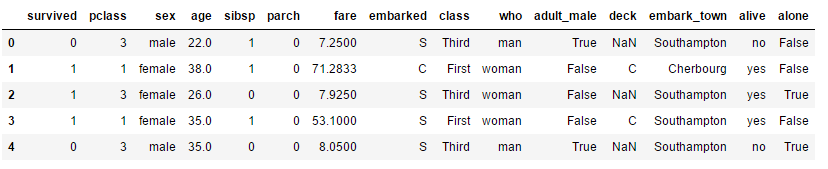
df = sns.load_dataset("titanic")
df.head()
feature_names = ["pclass", "age", "sex"]
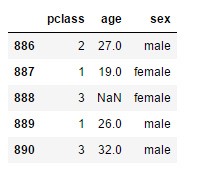
dfX = df[feature_names].copy()
dfy = df["survived"].copy()
dfX.tail()
from sklearn.preprocessing import LabelEncoder
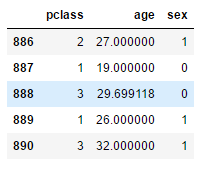
dfX["sex"] = LabelEncoder().fit_transform(dfX["sex"])
dfX["age"].fillna(dfX["age"].mean(), inplace=True)
dfX.tail()
from sklearn.preprocessing import LabelBinarizer
import pandas as pd
dfX2 = pd.DataFrame(LabelBinarizer().fit_transform(dfX["pclass"]),
columns=['c1', 'c2', 'c3'], index=dfX.index)
dfX = pd.concat([dfX, dfX2], axis=1)
del(dfX["pclass"])
dfX.tail()
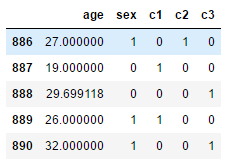
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
X_train, X_test, y_train, y_test = train_test_split(
dfX, dfy, test_size=0.25, random_state=0)
print(len(dfX), len(X_train), len(X_test))
model = DecisionTreeClassifier(
criterion='entropy', max_depth=3, min_samples_leaf=5).fit(X_train, y_train)

command_buf = io.StringIO()
export_graphviz(model, out_file=command_buf, feature_names=[
'Age', 'Sex', '1st_class', '2nd_class', '3rd_class'])
graph = pydot.graph_from_dot_data(command_buf.getvalue())[0]
image = graph.create_png()
Image(image)
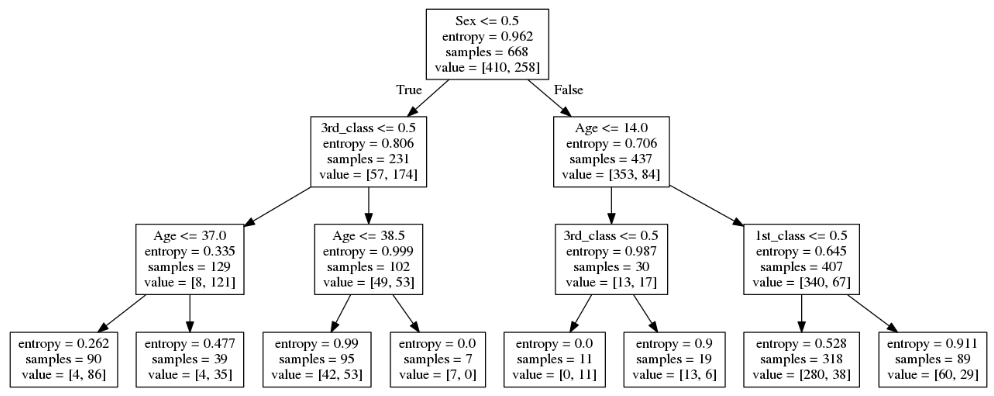
print('train==>')
print(confusion_matrix(y_train, model.predict(X_train)))
print('test==>')
print(confusion_matrix(y_test, model.predict(X_test)))

from sklearn.metrics import classification_report
print(classification_report(y_train, model.predict(X_train)))
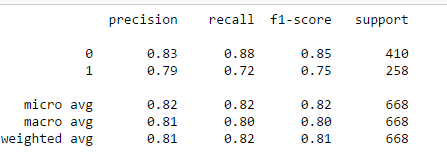
print(classification_report(y_test, model.predict(X_test)))
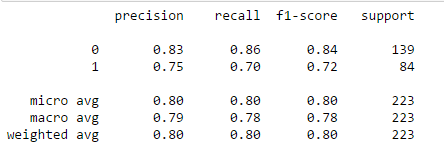
참고 자료
https://datascienceschool.net/view-notebook/16c28c8c192147bfb3d4059474209e0a/
댓글